The AlertKick blog
Field notes on alerting, eBPF, and AI ops
Opinionated, practical, sometimes impolitic writing on modern monitoring - from the team building AlertKick.

The best open-source eBPF tools in 2026: what to use for tracing, security, and networking
A field guide to the eBPF ecosystem's most useful open-source projects - bpftrace, bcc, Falco, Tetragon, Cilium, Inspektor Gadget, ebpf_exporter, bpftop, and pwru - what each one is actually for, what it costs to operate, and how to pick.
Read the post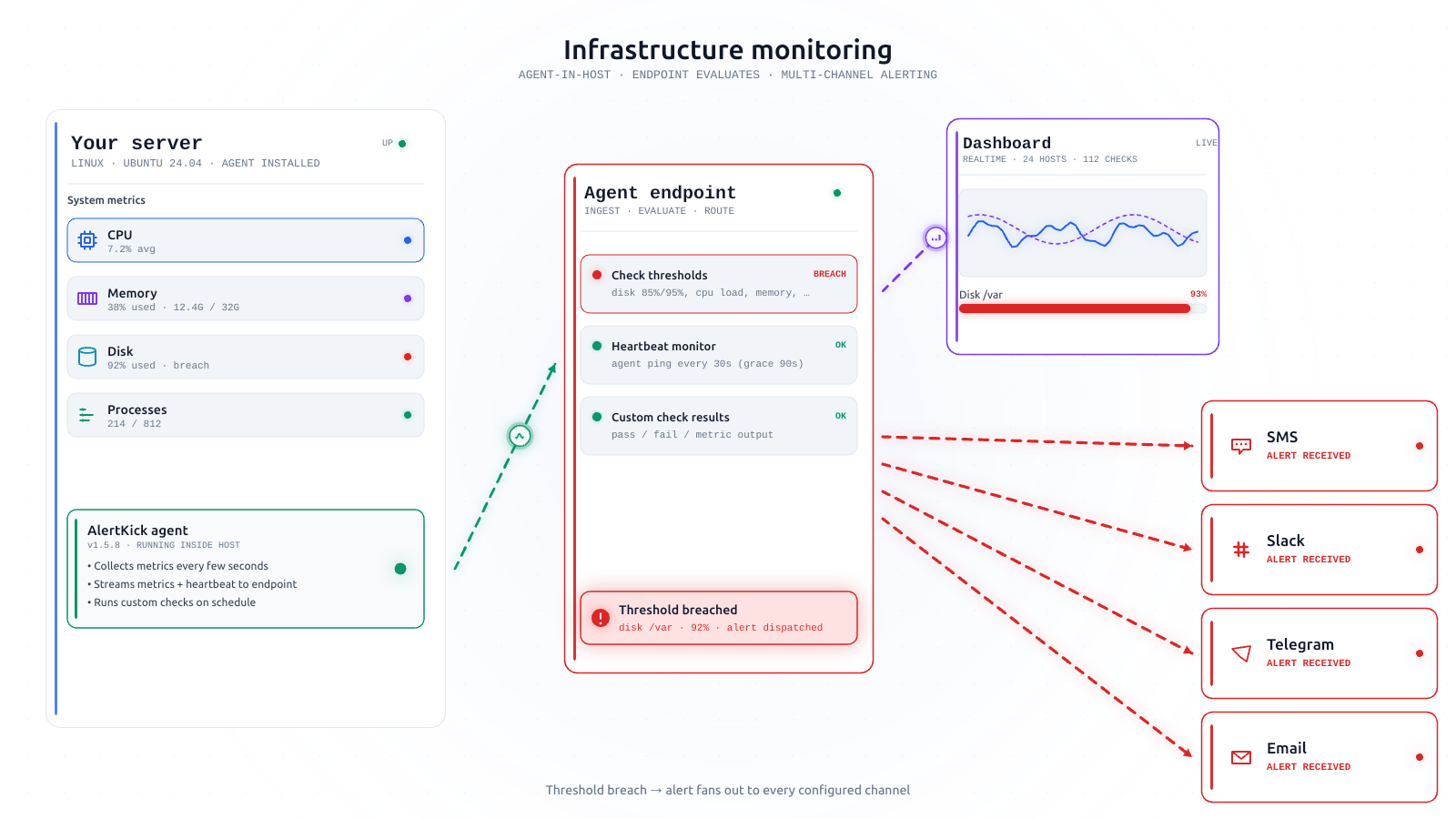
Getting started with bpftrace: 12 one-liners that answer real production questions
A practical bpftrace tutorial for Linux engineers: install it, understand probes and the five-minute version of the language, then twelve copy-paste one-liners for tracing processes, file opens, network connections, slow disks, and kills - each tied to the production question it answers.
Falco rules explained: syntax, custom rules, and tuning out the noise
How Falco rules actually work - conditions, macros, lists, and exceptions - with worked examples: writing a custom rule from scratch, overriding a stock rule without forking it, and a practical week-one tuning workflow that cuts the noise without blinding you.
How to configure auditd on Linux: rules that catch attackers instead of filling disk
A practical auditd guide for Ubuntu, Debian, and RHEL: install and enable it, understand auditd.conf and rules.d, write file-watch and syscall rules that auditors and incident responders actually use, query the log with ausearch and aureport, and keep the noise from eating your disk.
How to detect rootkits on Linux: hidden modules, hidden processes, ld.so.preload
Rootkits are defined by hiding, and hiding leaves seams. Three checks that catch the common Linux rootkit families - LKM modules hidden from lsmod, processes hidden from /proc, libc hooks in /etc/ld.so.preload - with copy-pasteable commands, the false positives that bite DIY versions, and why a scan every 5 minutes beats a scan when you remember.
How to install and configure Falco on Ubuntu and Debian (2026 guide)
A complete, tested walkthrough for installing Falco on Ubuntu 24.04 or Debian 13: choosing the right driver (modern eBPF vs kernel module), configuring falco.yaml, wiring outputs to a file, syslog, or a webhook, and verifying detections actually fire.
How to monitor SSL certificate expiry (openssl one-liners, a cron script, and the proper fix)
Expired TLS certificates still take down real sites in 2026. Here is the full toolkit: openssl one-liners to check any cert now, a cron script that emails before expiry, the failure modes that make DIY checks lie to you, and how to get continuous monitoring for free.
Linux server security checklist: 20 steps, each with a verify command
A copy-pasteable Linux server security checklist ordered by payoff: 20 steps covering SSH, firewall, updates, accounts, kernel, auditing, containers and drift - each with the command to apply it AND the command to prove it stuck. Works on Ubuntu, Debian and RHEL-family. Includes a free read-only audit script that grades your server.
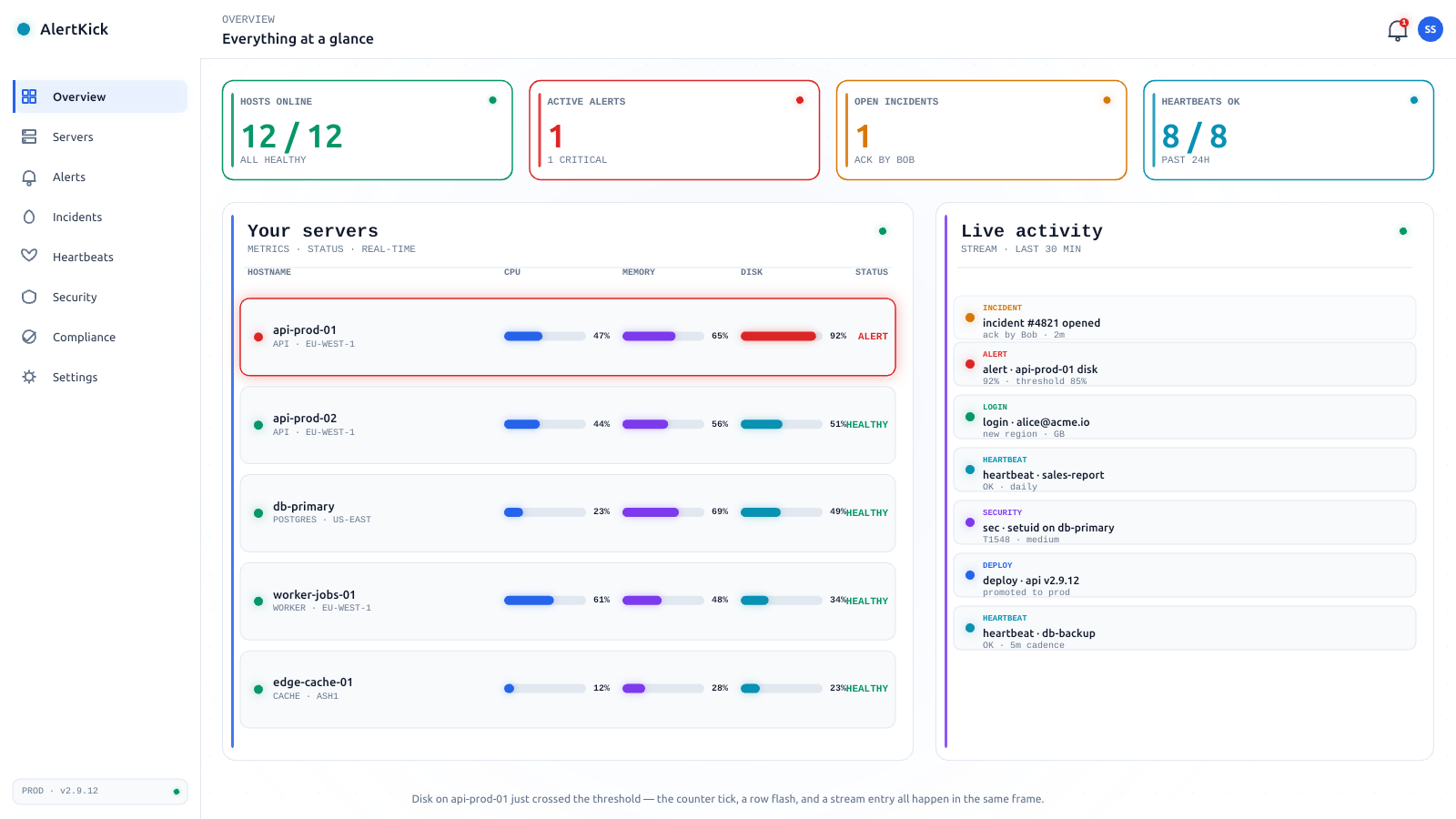
How to set up website monitoring in 2026: the complete checklist
A practical guide to monitoring a website properly: the six checks that matter (uptime, content, SSL, domain, response time, scheduled jobs), sensible intervals and thresholds, the alerting rules that prevent both missed outages and 3 AM noise, and how to get the whole baseline free.
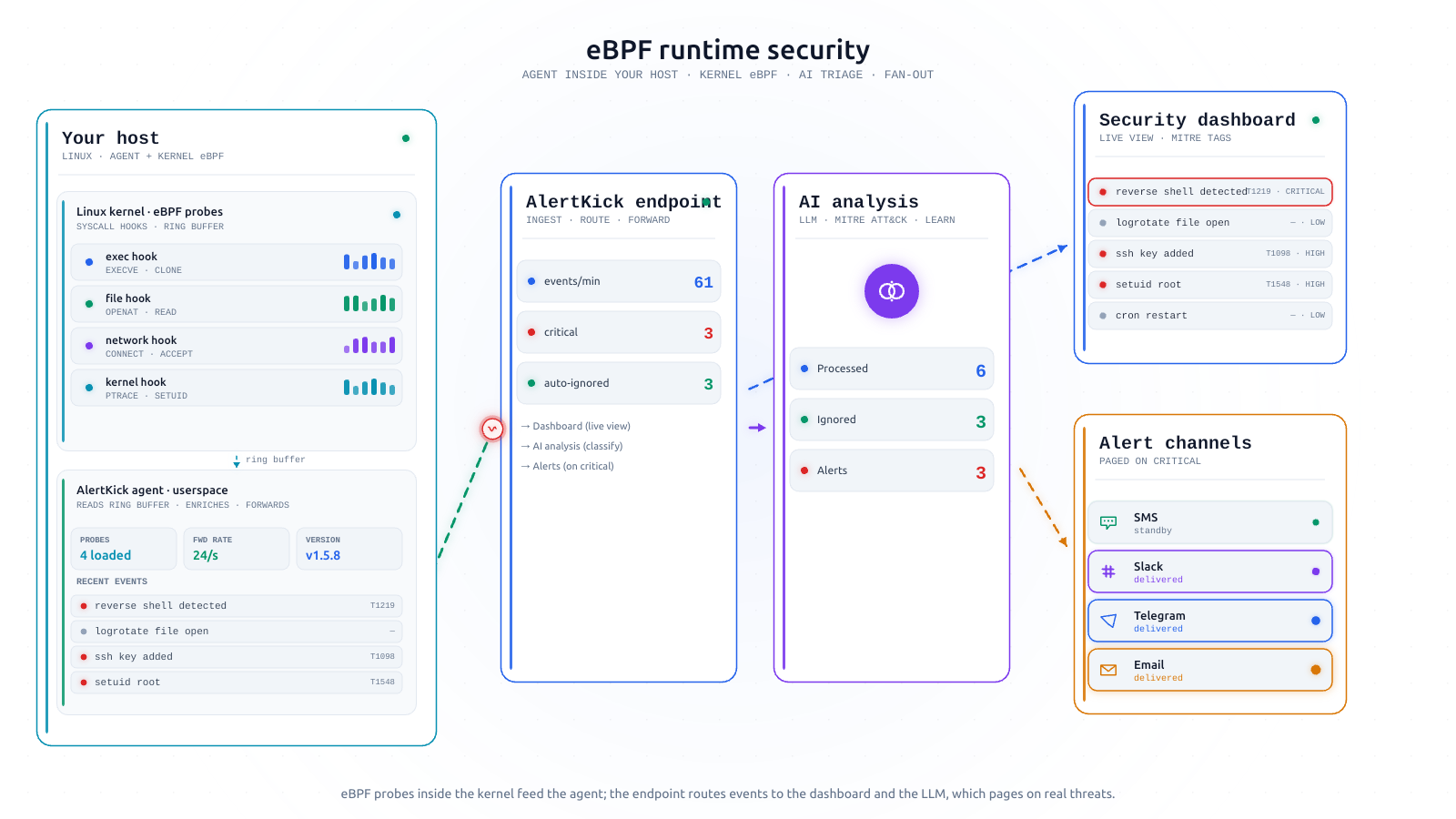
AIDE vs Tripwire vs eBPF: file integrity monitoring that tells you who
AIDE and Tripwire tell you on Tuesday what changed on Sunday. A comparison of the classic scan-based FIM tools with kernel-level eBPF file integrity monitoring - what each catches, what each misses, and which fits your servers.
Debian 13 server hardening checklist: minimal install to defensible
A copy-pasteable hardening checklist for Debian 13 (trixie): sudo and SSH lockdown, nftables/ufw, unattended-upgrades, sysctl settings, and auditd - with the Debian-specific gotchas that Ubuntu guides skip.
Grafana OnCall is archived: what self-hosted users should do next
Grafana OnCall OSS entered maintenance mode in March 2025 and the repository was archived on 2026-03-24. If your team's paging still runs through a self-hosted OnCall install, here is what actually breaks, what your options are, and a practical migration checklist.
Is my Linux server hacked? A step-by-step check
A practical runbook for the worst feeling in ops: something's off and you don't know why. Check sessions, processes, network, persistence, and file changes in order - with the exact commands - and know what to do if you find something.
Opsgenie shuts down in April 2027: a migration guide for small teams
Atlassian ends Opsgenie support on 5 April 2027 - access stops and unmigrated data is deleted. What the deadline actually means, what the Jira Service Management path costs a small team, and how to decide what to move to.
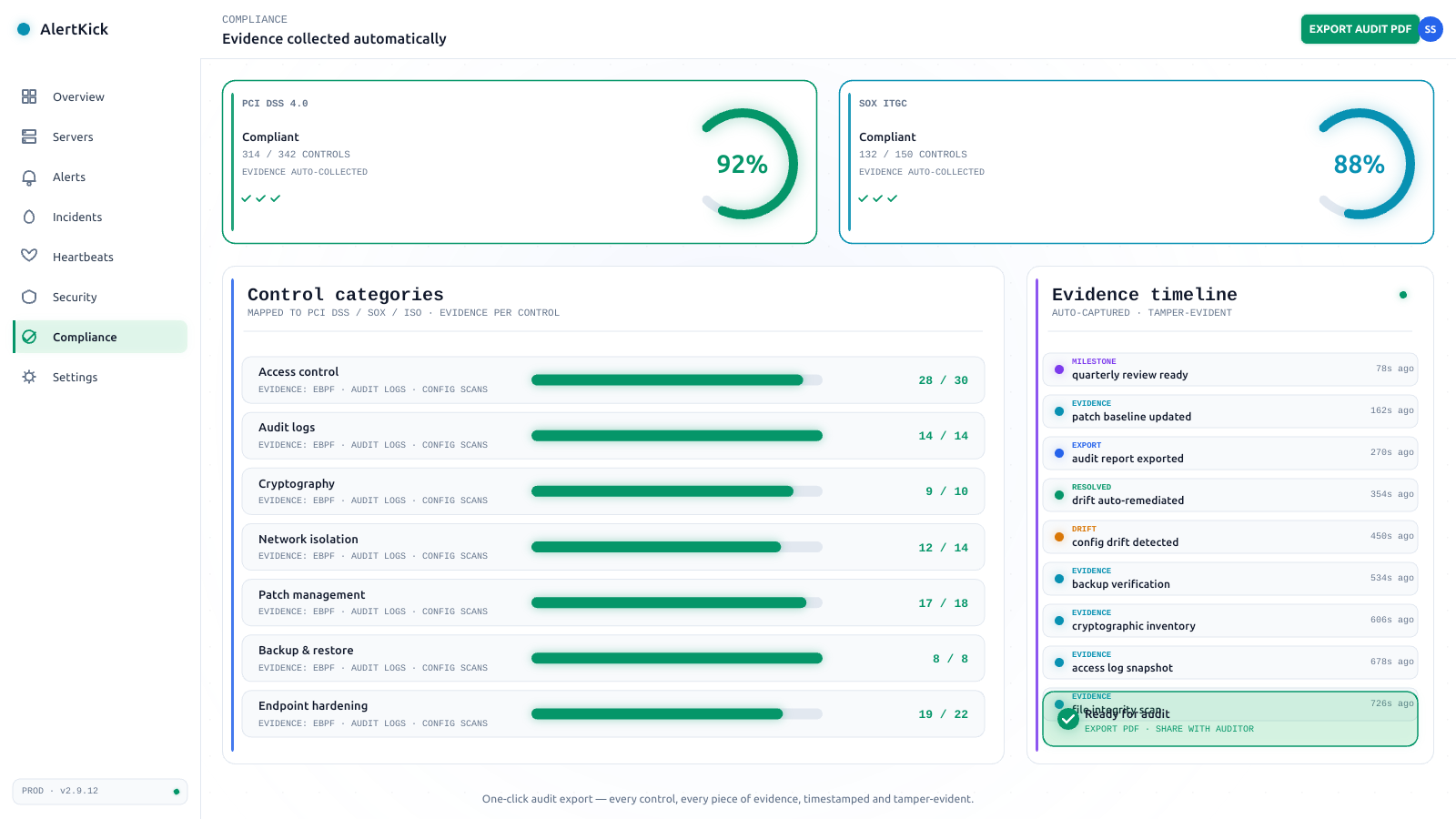
PCI DSS file integrity monitoring: what Requirement 11.5.2 actually demands
PCI DSS requires a change-detection mechanism - FIM in practice - on critical files, with comparisons at least weekly and alerts on unauthorized modification. What counts as critical, why weekly is a floor not a target, and how to satisfy it without an enterprise tool.
Reducing alert fatigue: a practical guide for small on-call teams
Alert fatigue isn't a discipline problem - it's a design problem. How to audit your alerts, the four rules that make pages trustworthy again, what fair rotations look like on a team of five, and where AI triage honestly helps.
Your server is at 100% CPU: finding and removing a crypto miner
A step-by-step removal runbook for cryptojacking on Linux: identify the miner (even when it hides), kill it properly, dig out the persistence that will bring it back, close the entry hole, and detect the next one in minutes instead of weeks.
RHEL 9 / AlmaLinux / Rocky server hardening checklist
A copy-pasteable hardening checklist for the RHEL 9 family: SSH lockdown, firewalld zones, dnf-automatic security updates, keeping SELinux enforcing (really), sysctl settings, and auditd - plus the drift problem no checklist survives.
SOC 2 logging requirements: what auditors actually ask for
SOC 2 has no official list of required logs - it's criteria-based, and auditors sample evidence. Here's what they ask for in practice at the host level: access logs, change detection, alerting proof, retention - and how to have it ready instead of reconstructing it.
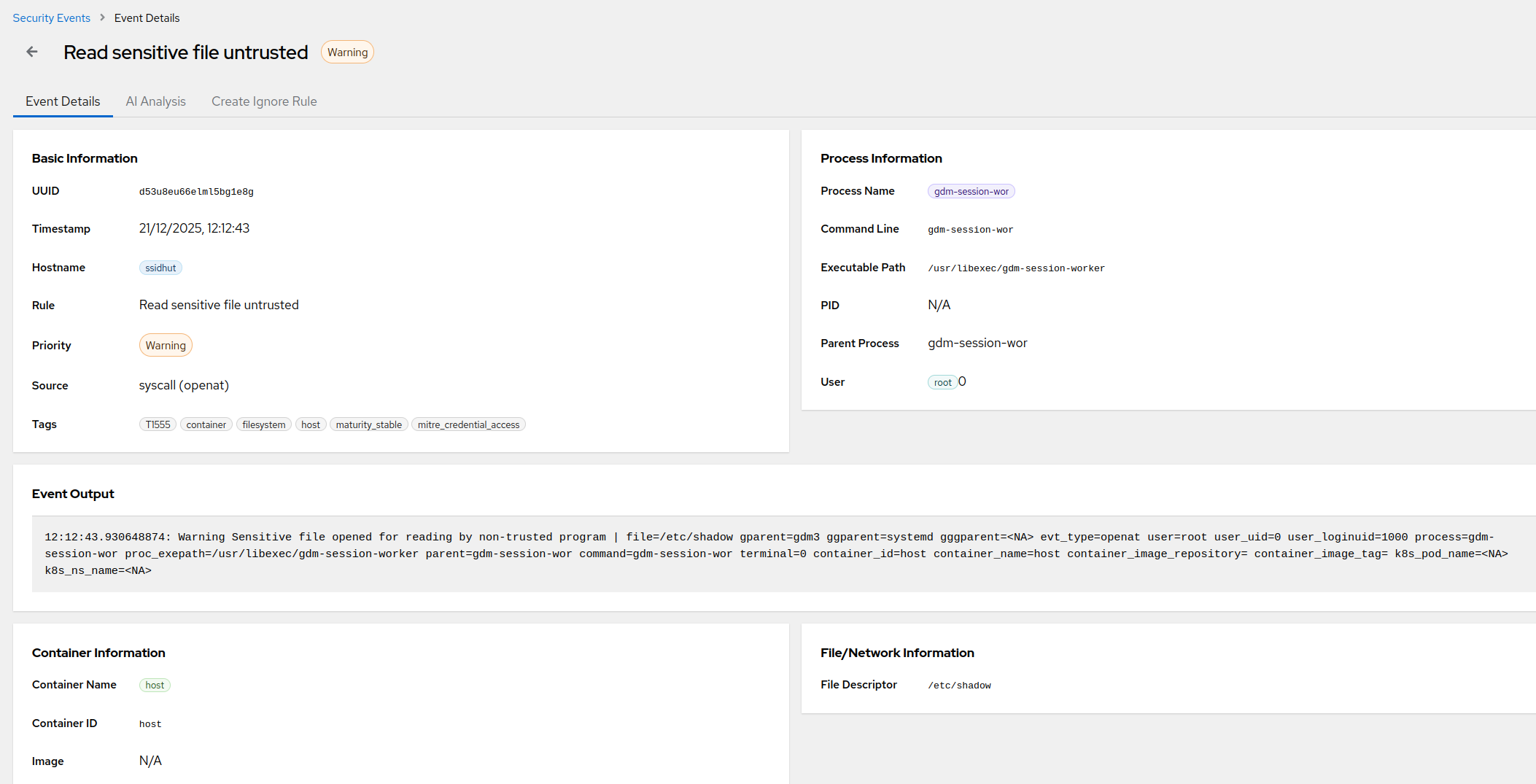
How to get notified when someone logs into your server over SSH
Three DIY ways to get an SSH login notification on email, Slack, or Telegram - PAM hooks, auth.log watchers, and their failure modes - plus what it takes to make login alerting something you can actually trust.
Ubuntu 24.04 server hardening checklist: from fresh install to defensible
A copy-pasteable hardening checklist for Ubuntu 24.04 LTS: users and SSH, firewall, automatic updates, kernel and shared-memory settings, auditing - ordered by payoff, with the reasoning for each step and how to keep the box hardened after day one.
Uptime Kuma is great. Here's what it can't tell you.
An honest look at the limits of self-hosted uptime monitoring: the watcher that shares fate with the watched, the 3 AM problem, and the difference between knowing your site is down and knowing your server is compromised.
UptimeRobot alternative: free uptime monitoring you can use for work
UptimeRobot's free plan has been personal-use only since its October 2024 terms change - business monitoring requires a paid plan. If that email or that clause sent you searching, here's a free tier that explicitly allows commercial use, and what to check before you switch.
A Wazuh alternative for small teams: security monitoring without the second job
Wazuh is a capable open-source SIEM - and a demanding one. If you're a small team eyeing the indexer requirements, the rule tuning, and the maintenance surface, here's an honest comparison and a lighter path to Linux threat detection.
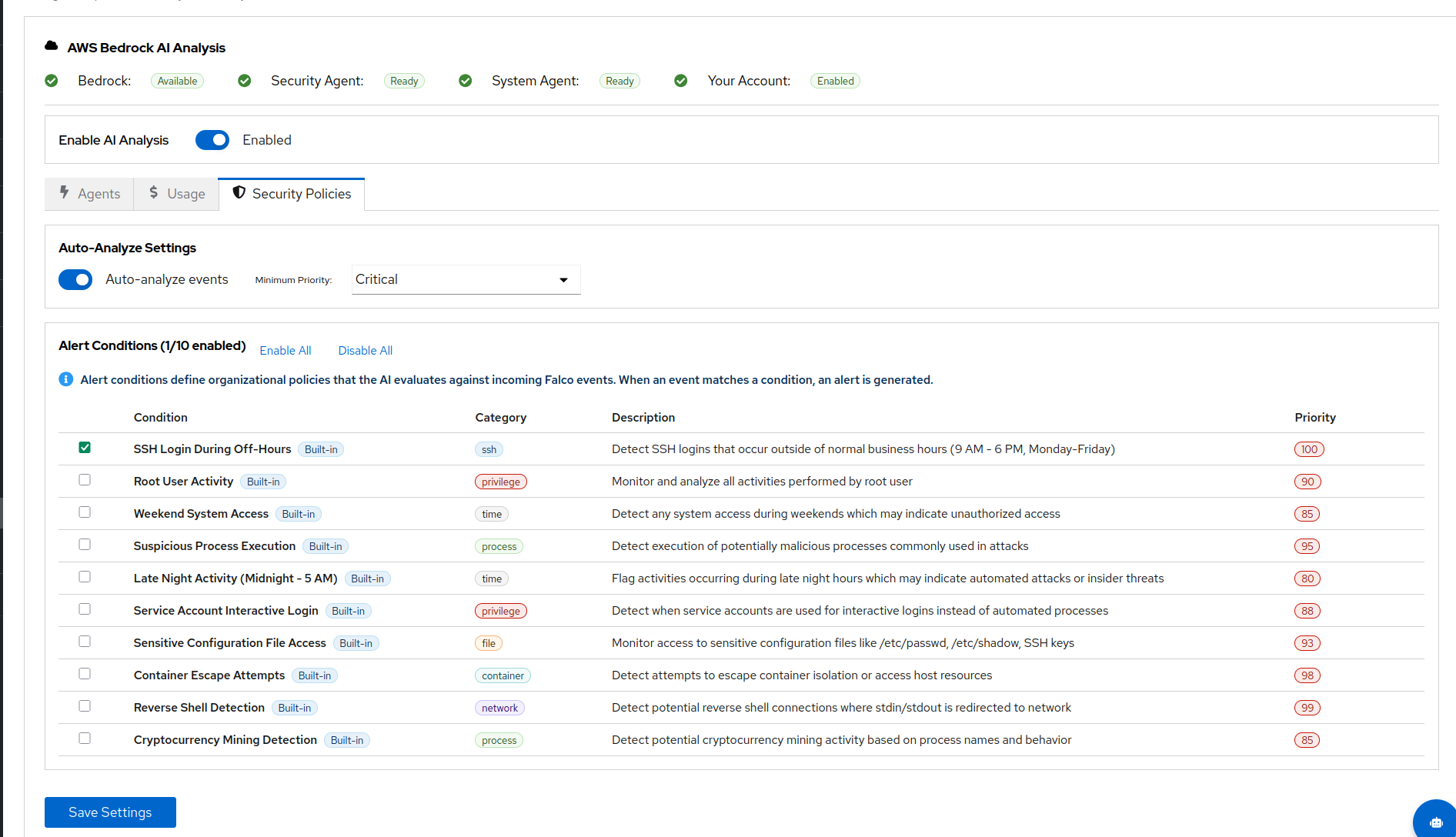
Running incident triage from your AI assistant: a walkthrough
AlertKick ships an MCP server, which means your AI assistant can query alerts, inspect hosts, acknowledge pages, and dig into security events in natural language. Here's what that actually looks like during an incident.
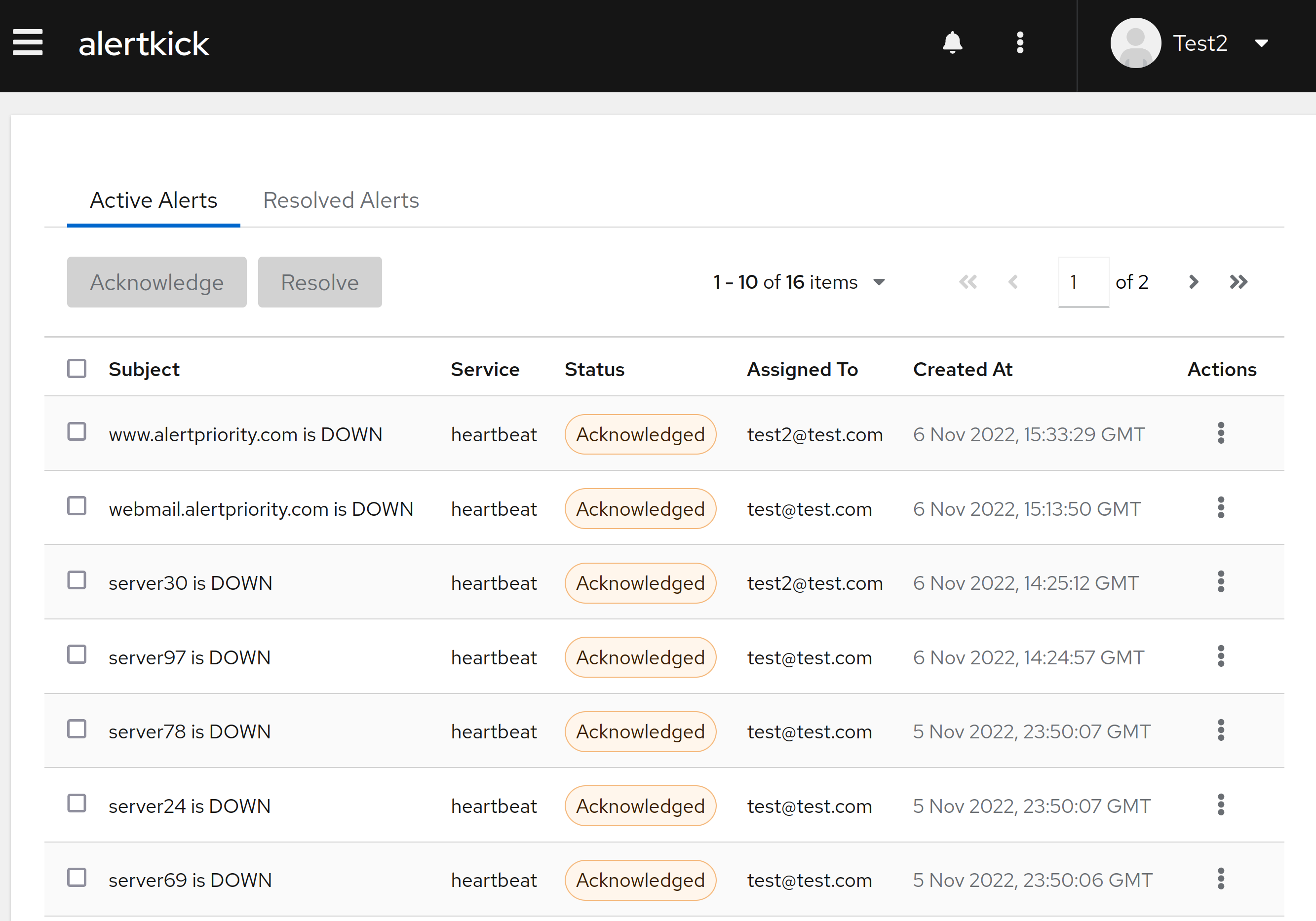
The real cost of building your own monitoring stack
Stitching together your own monitoring is a perfectly valid choice. It's just not a free one. Here's where the cost actually shows up - in time, attention, and the person on your team who stops being an engineer and starts being the monitoring engineer.
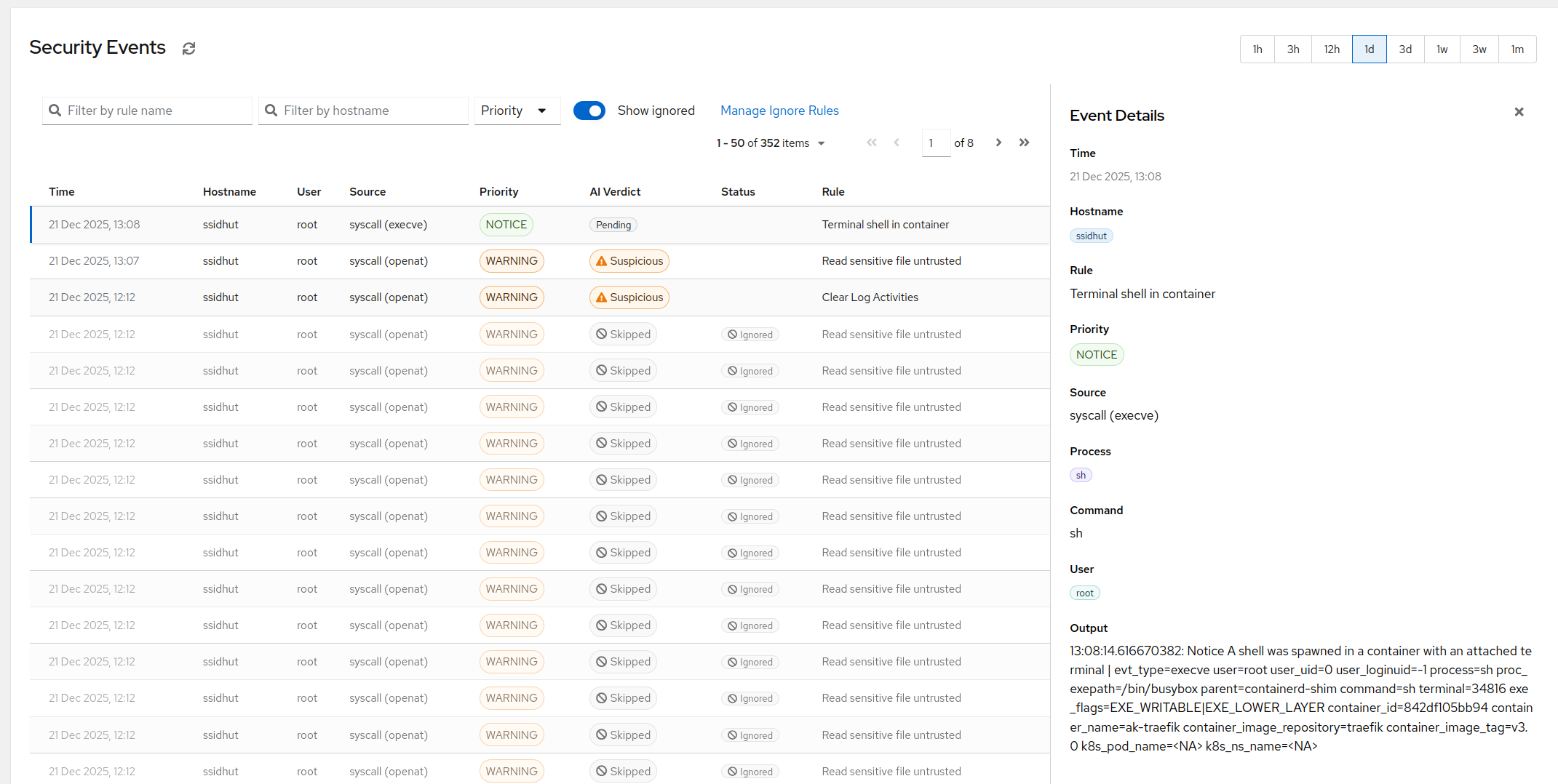
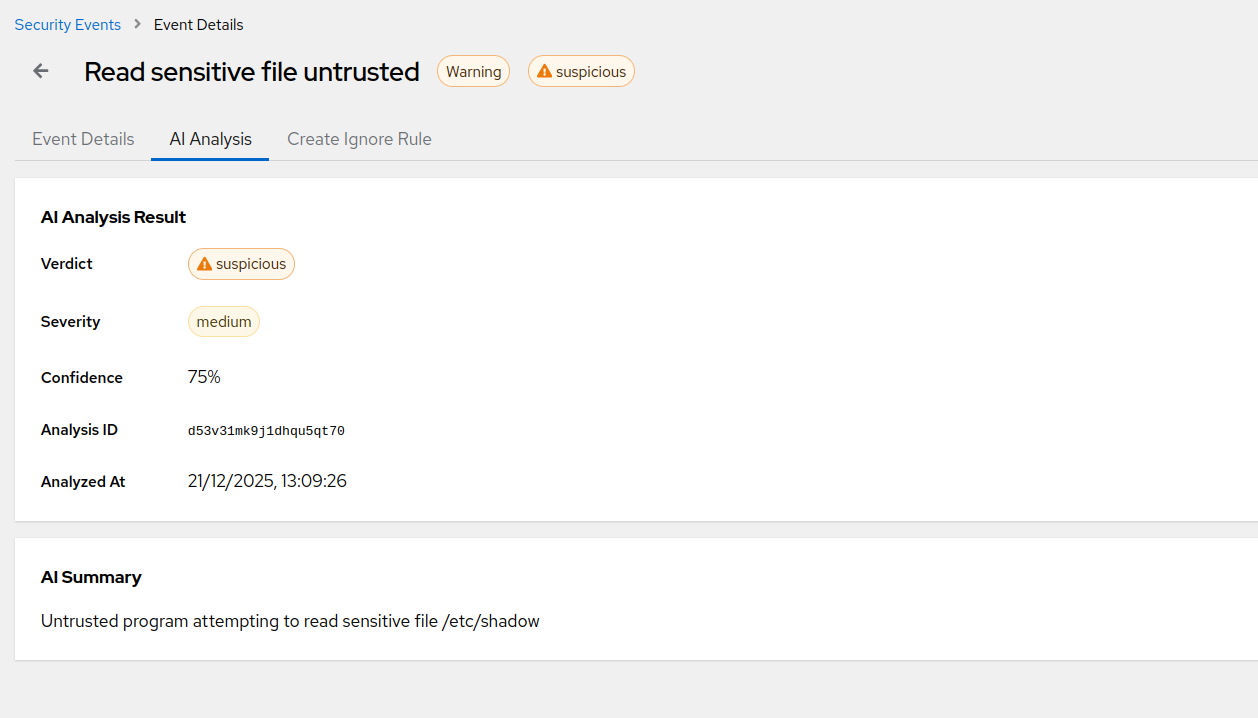
How AI triage cuts most of your eBPF alert noise
Raw eBPF events are noisy by design - a useful ruleset will fire dozens of times a day on a healthy host. An AI triage layer sitting between the detection and the alert channel is what makes the whole thing usable. Here's how ours works.
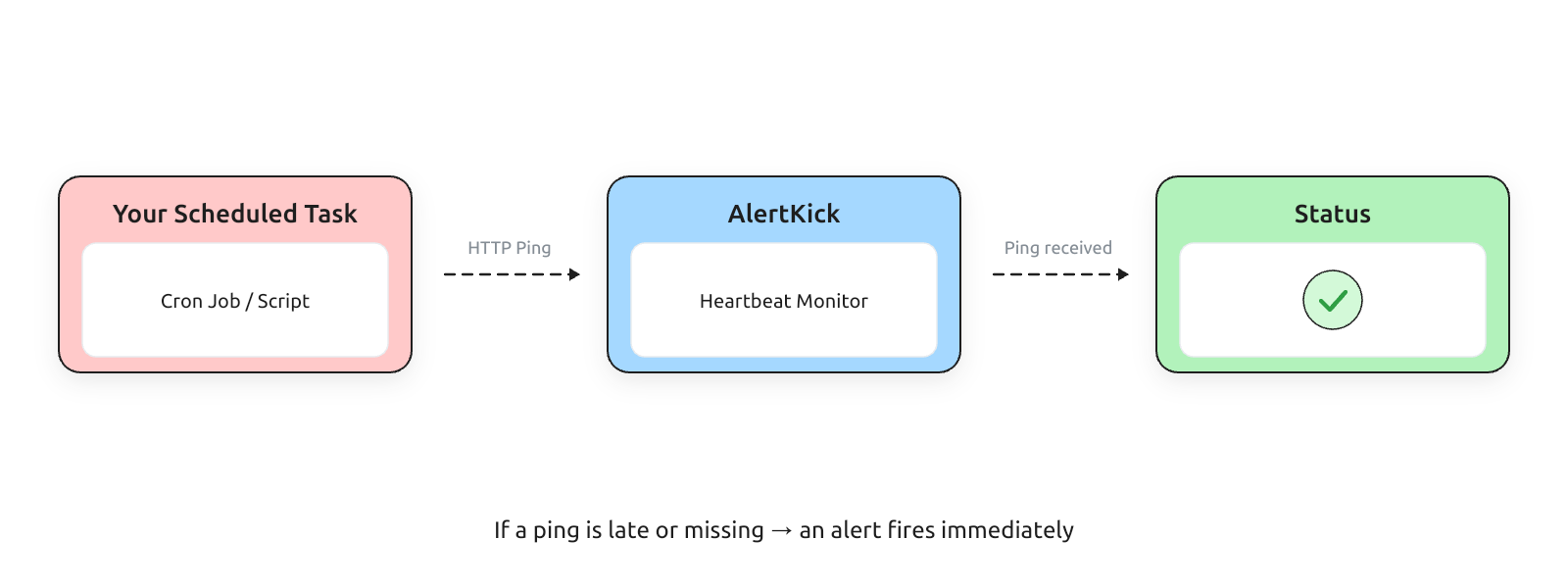
Heartbeat monitoring: the single line of script that saves your backups
The most under-used monitoring pattern in small-team infrastructure is the heartbeat - a scheduled job that pings a URL on success, and a monitor that alerts when the ping stops arriving. Add one line to your scripts, never miss a silent failure again.
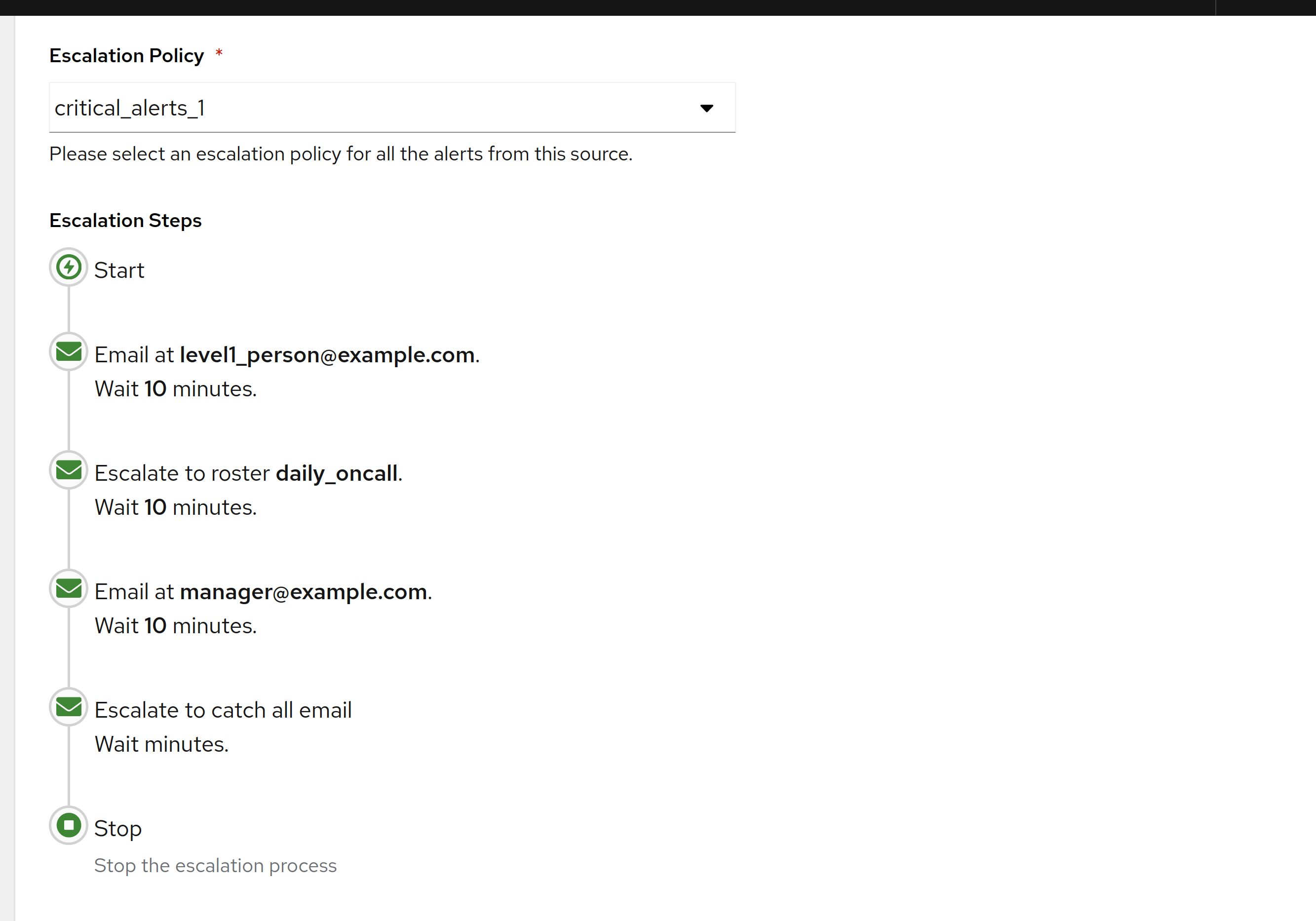
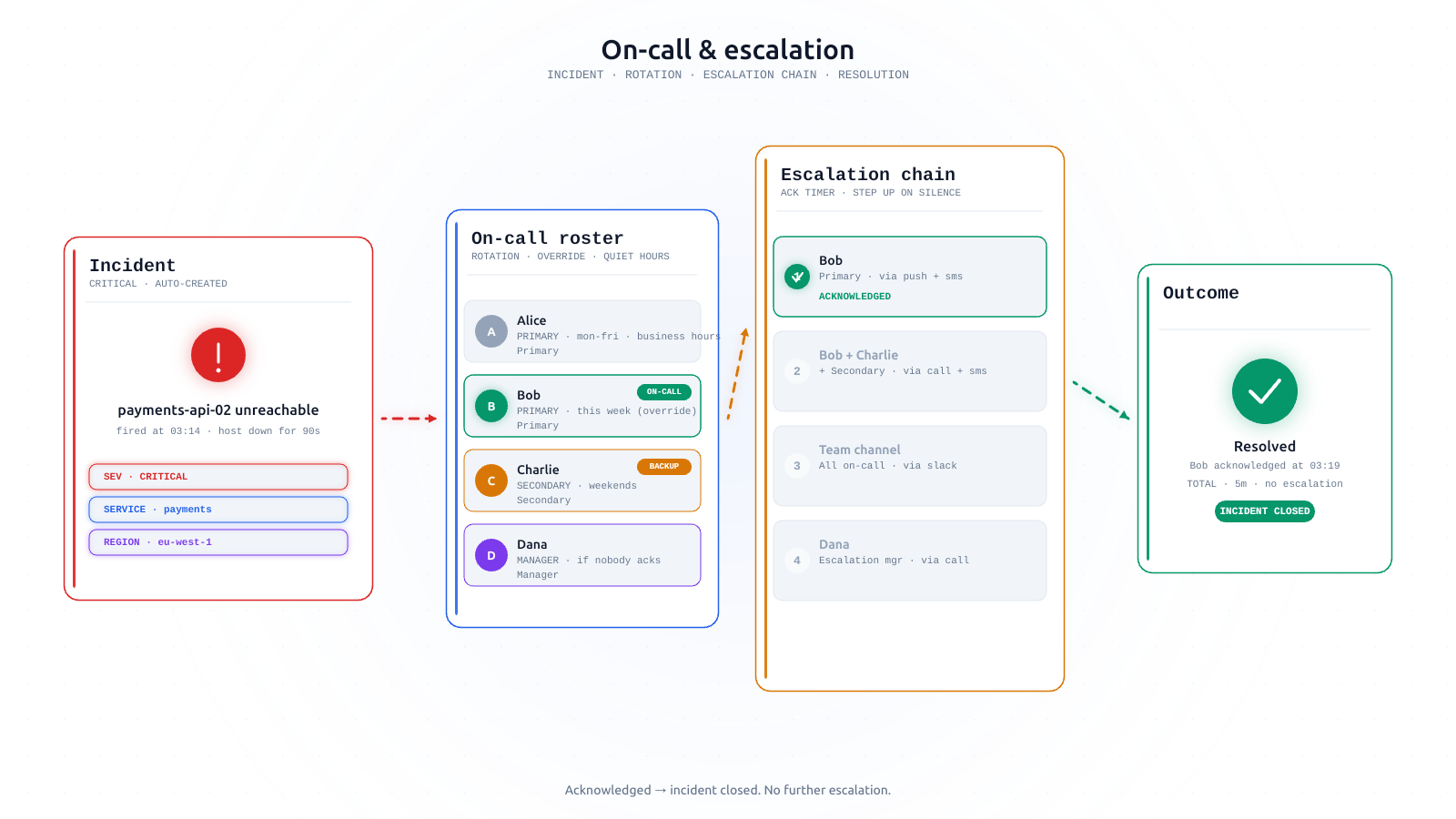
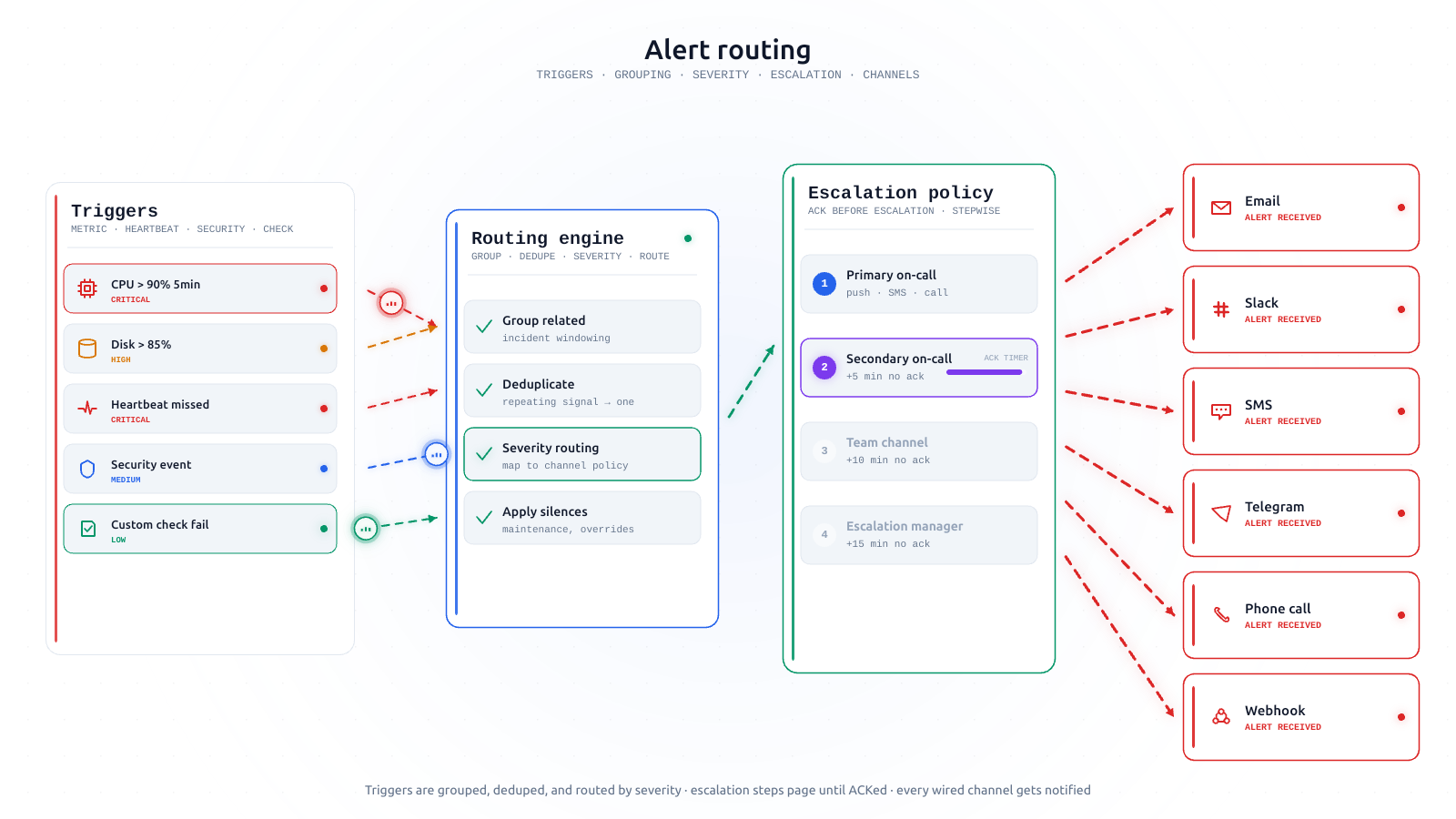
The escalation levels AlertKick ships by default
On-call escalation policies don't need to be complicated. AlertKick ships a small set of sensible defaults - three levels, one rotation, one set of quiet hours. Here's what each level is for and why that's enough.
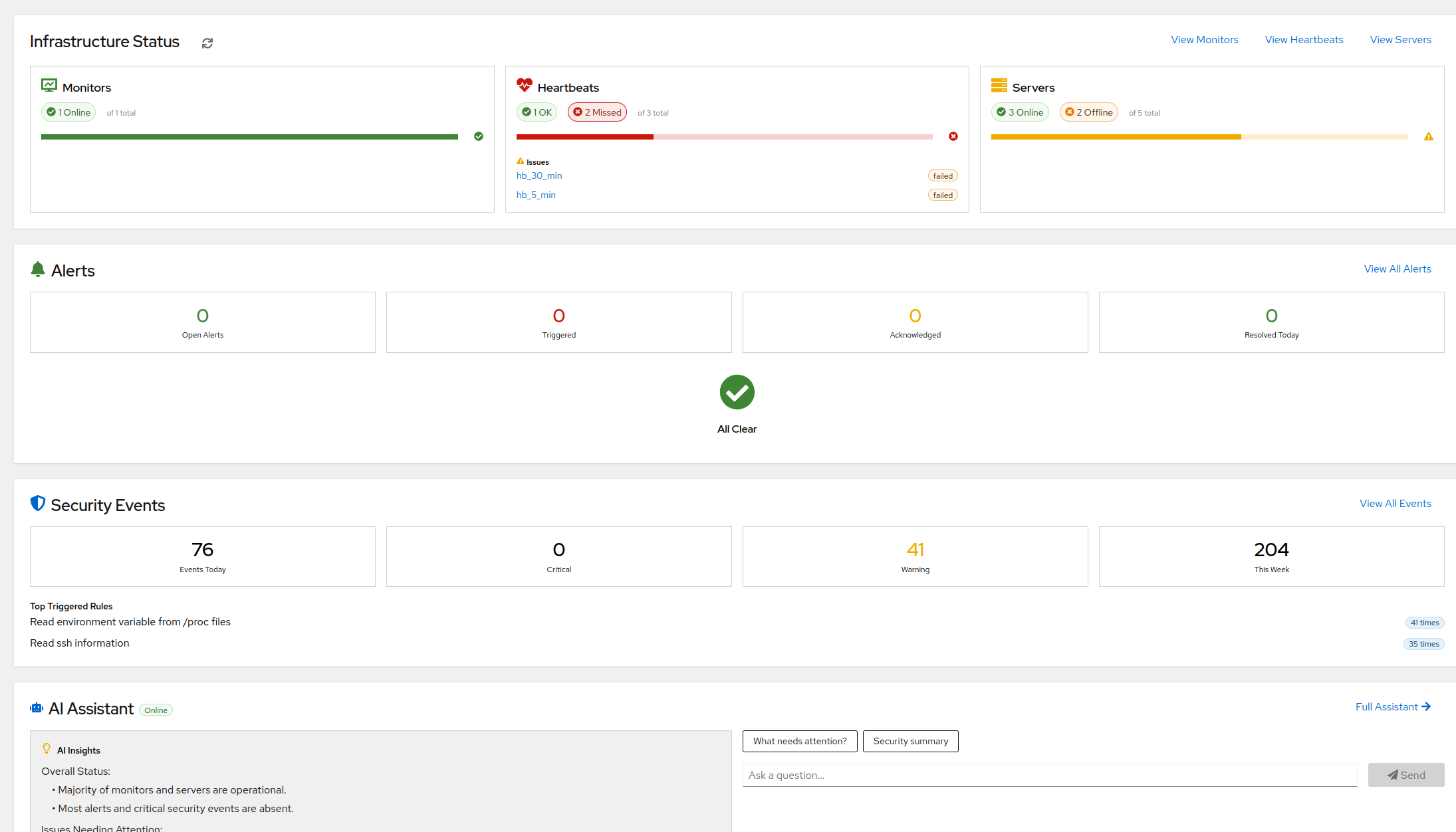
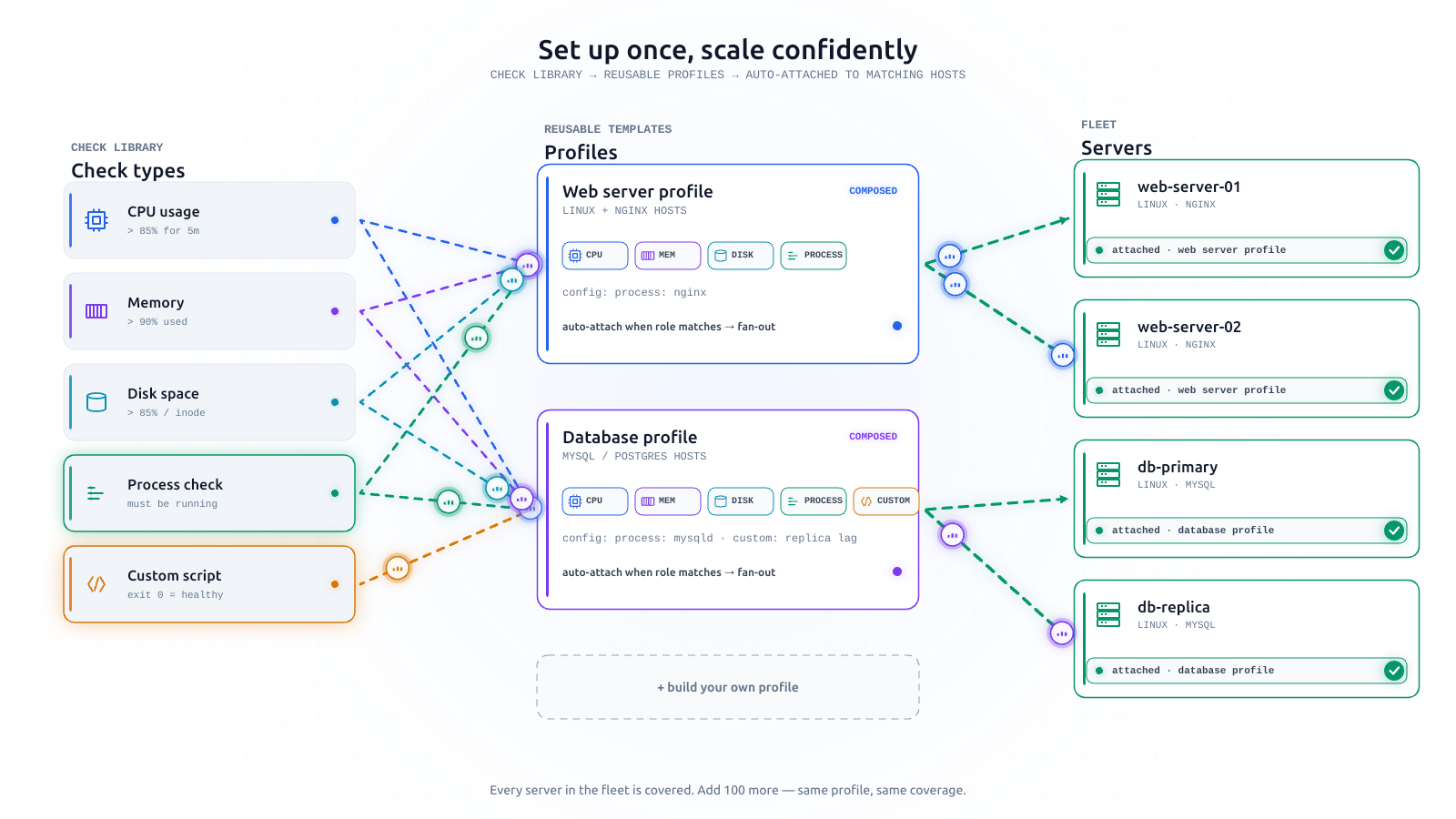
The checks every server should have on day one
There's a short list of things that break a Linux server and a shorter list of checks that catch most of them. AlertKick ships all of them on by default. Here's the list, and why it's the list.
What eBPF actually is - and why it's finally practical to run
eBPF is the reason modern runtime security works. Historically it's come with an enterprise price tag and a team to match. Here's what it does, why that's changed, and what AlertKick gives you on day one.
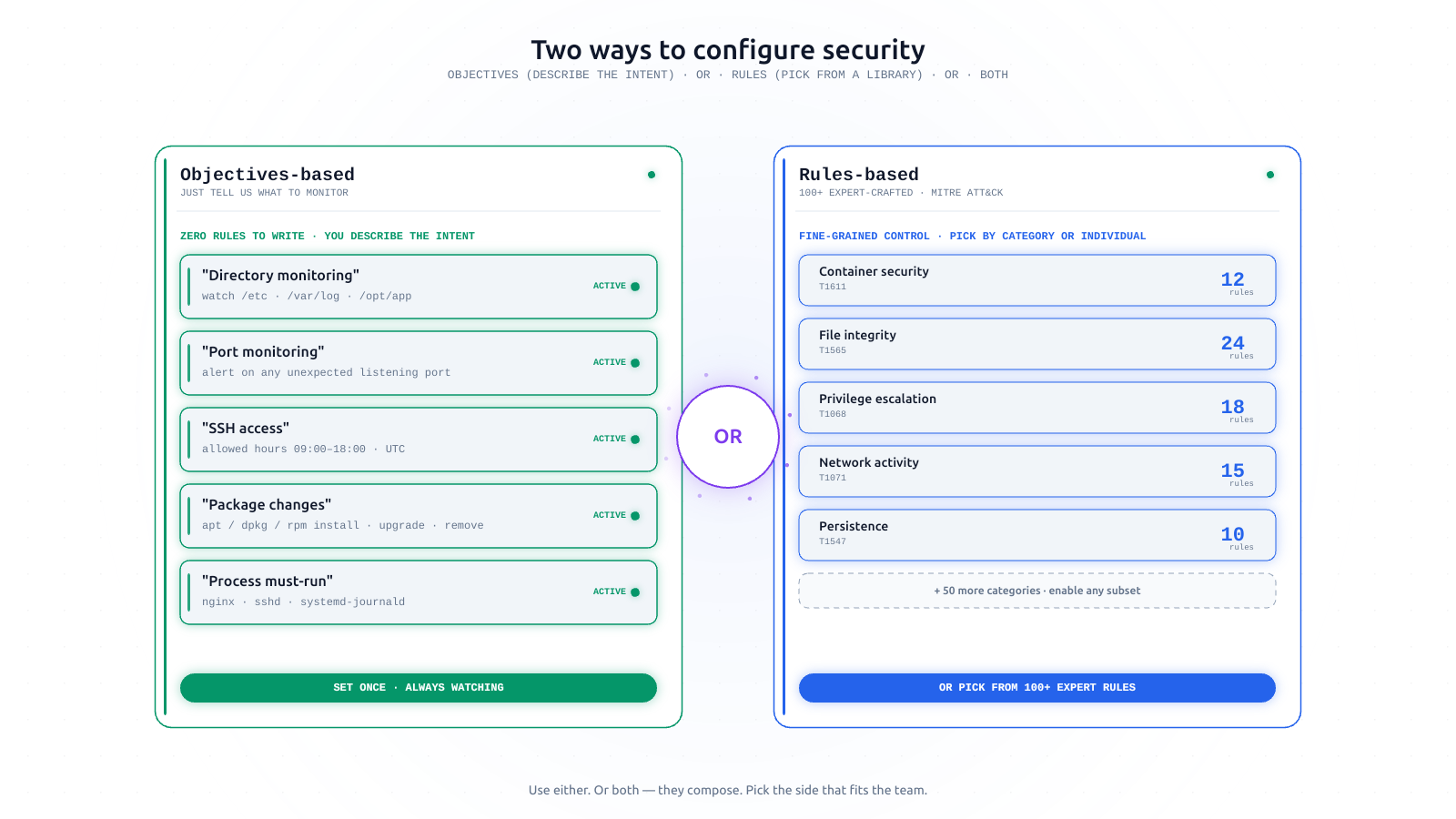
Why AlertKick is opinionated, not configurable
Every knob in a monitoring tool is a decision somebody has to make. Most of those decisions have a right answer. AlertKick ships the right answer by default - so you don't have to be the person figuring it out.
Why we built AlertKick
Monitoring infrastructure is a pain in the ass. It takes numerous tools, each needing code and config, and once it breaks the team ends up with a dedicated monitoring person whose only job is keeping the stack alive. That's not a good outcome. So we built something opinionated.