The real cost of building your own monitoring stack
Stitching together your own monitoring is a perfectly valid choice. It's just not a free one. Here's where the cost actually shows up - in time, attention, and the person on your team who stops being an engineer and starts being the monitoring engineer.
The AlertKick team
There’s a version of the monitoring conversation that ends with someone on the team saying “we can just build this ourselves”. They’re usually right - you can build it yourself. The components are all open source, the documentation is comprehensive, and for any given sub-problem there’s a popular piece of software that solves it well. An experienced engineer can get a working version of “a monitoring stack” up in a weekend.
The thing the weekend-version conversation leaves out is what happens over the next eighteen months. Someone ends up assembling that stack, maintaining that stack, and eventually becoming the stack - the oral-tradition owner of how half a dozen components fit together. That last part is where the real cost lives, and it doesn’t show up on any line item.
This post is about where the cost actually is, and why building it yourself is a valid choice for some teams and a trap for most others.
The shape of the DIY stack
If you’re going to build your own monitoring, the minimum viable version has most of these components:
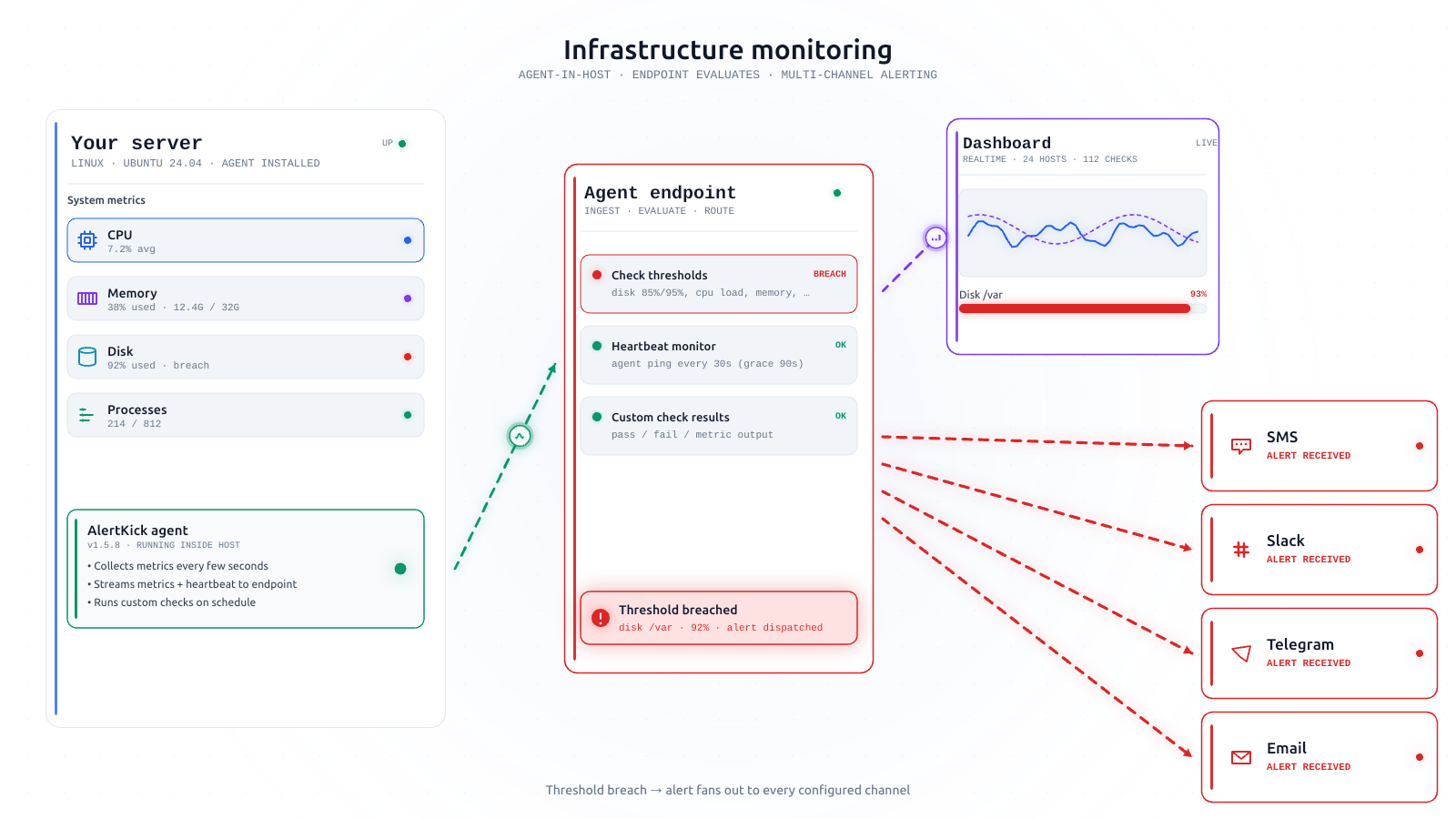
- A metrics agent on every host, scraping CPU, memory, disk, and whatever domain-specific endpoints you expose.
- A time-series database to store those metrics.
- A rules evaluator that queries the database on a schedule and fires alerts when expressions match.
- An alert router that takes those alerts and sends them somewhere useful.
- A dashboard tool for visualising the metrics.
- A log aggregator for the things metrics don’t capture.
- A synthetic uptime checker for external endpoints.
- A cron heartbeat monitor for scheduled work.
- An on-call scheduler for who gets paged when.
- A chat bot or email integration so alerts land somewhere a human will actually see them.
- A runtime security component if you care about that.
Every one of those is a real piece of software that does its job well. They do not, however, speak the same data model. Between each pair of components is glue: a config file, a webhook, a format converter, a translation from this tool’s alert schema to that tool’s ticket schema.
You will write most of that glue. It will break whenever any of the components updates its format. Every breakage will look, to whoever’s on-call, like a monitoring outage.
Where the cost shows up
Initial assembly
The weekend to get “a working version” is real and achievable. It’s not actually that hard. You’ll have metrics flowing, a dashboard open, an alert firing into a chat channel, and a sense of satisfaction by Sunday night.
You’ll also have made about forty implicit decisions - what to scrape, at what interval, with what labels, at what retention, with what cardinality limits, through what aggregation rules. Every one of those decisions has a right answer, and the weekend version almost certainly doesn’t have the right answer on any of them yet. The first time you run into the wrong answer in production, you’ll spend a week untangling it.
Call the assembly cost one person, two weeks of full engineering time to get from “a working version” to “a version you’d trust to wake somebody at 3 AM”.
Ongoing maintenance
Each of the components you stitched together ships updates. Those updates fix bugs, patch security issues, deprecate features, change defaults. On average, across a stack of eight or ten components, something that affects you will land every couple of weeks. Sometimes you can skip the upgrade. Sometimes you can’t.
Call the maintenance cost one person, one day per two weeks, indefinitely.
That number is optimistic. It assumes upgrades go smoothly, that none of the glue breaks, that nobody’s rewritten the config format between minor versions, that the metrics storage didn’t silently corrupt itself after an OOM.
The config sprawl tax
A monitoring stack is a living configuration. Every new service gets rules. Every new host gets labels. Every new alert gets routing. Every new incident produces a post-mortem that adds an alert to catch the thing you missed this time.
Month one, the rules directory has a dozen files. Month twelve, it has a thousand. The thousand are not all well-maintained. Half of them were written for services that have since been deleted. A quarter of them haven’t fired in eighteen months. None of them have documentation explaining why the threshold is what it is.
Cleaning up this config requires a dedicated project nobody ever wants to run. So you don’t. And the pile grows.
The “monitoring person”
Here is the cost that isn’t on any invoice: once the stack is non-trivial, someone on your team becomes the person who owns it. It’s whoever built the weekend version, plus however much of the sprawl they’ve accumulated.
That person’s calendar starts filling up with monitoring-related work. Upgrading components. Debugging why the alert router ate a page. Explaining to a new hire how to add a rule for their service. Fielding questions about why the metric they expected to see isn’t there. Redesigning the tagging schema when the team reorg happens.
At a certain threshold - usually around a hundred servers or so - that work fills more than half their week, and you now have a monitoring engineer. They cost what a senior engineer costs, because they are a senior engineer, and they’re no longer working on the thing your company actually makes. They are working on the tool that makes sure the thing your company actually makes keeps running.
This is a real and valid role. Every large engineering organisation has several of them. The mistake is assuming you’ll escape having one by being clever about the choice of open-source components.
The cost of the gaps between components
Even a well-maintained DIY stack has seams where the tools meet. The seams have bugs. Alerts get lost in them. Paging gets delayed in them. The cron-heartbeat component is on vacation while the metrics pipeline keeps working, and the cron that stopped running last week is silently unmonitored.
Every incident review that ends with “the alert was configured but didn’t fire” is an instance of this. These are unavoidable when you have eight separate components handling parts of the same problem. They are avoidable when you have one.
What all of that adds up to
For most teams, the DIY route typically costs:
- Two weeks of initial engineer time to reach production-trustworthy.
- One day per two weeks of ongoing maintenance.
- Slowly-growing attention tax from config sprawl.
- Eventually, some non-trivial fraction of one full-time engineer whose job becomes “the monitoring”.
- Periodic outages of the monitoring itself, each of which looks (during the outage) exactly like a failure of whatever the monitoring was watching.
At a senior engineering salary, the fully-loaded cost of this arrangement, conservatively, is tens of thousands of pounds a year. Often more. The “free” part was only the software licences. The labour was never free.
For a team that has or will have a dedicated observability function, that cost is fine - their job is operating this stack, and they’ll do it better than any vendor. For a team where nobody’s title says “SRE” or “observability”, it’s a trap. The engineer who ends up owning it is usually the one you least want to pull off product work.
Why AlertKick is what it is
The alternative is a product that makes the opinionated decisions for you. One agent per host, one data model, one dashboard, one escalation engine, one security engine. The decisions that come pre-made - what to monitor, what thresholds to use, what to suppress, what to escalate - are the ones AlertKick’s team made over years of SRE work, poured into the product as defaults.
You’re not paying us for software licences. You’re paying us to have already made two weeks of decisions, plus one day every two weeks of maintenance, plus some fraction of a monitoring engineer. It’s one predictable monthly bill - every feature included, not multiplied per host or per metric - so you can work out the payback period yourself. It’s short.
That’s not a dismissal of the DIY path. It’s an honest accounting of what that path costs, and a recognition that for most teams the maths doesn’t work. AlertKick is for the teams where the maths doesn’t work.
When to build it yourself anyway
There are teams for whom building it yourself is genuinely correct:
- If you already have an observability team. They will build you something tuned to your environment, and a generic vendor will be a downgrade.
- If your monitoring is itself your product. Infrastructure companies, platform companies, certain categories of managed service. The stack is the thing you sell.
- If your environment is specifically weird enough that generic assumptions will hurt you. Very large scale, very unusual workloads, regulatory-isolation requirements where data cannot leave your perimeter.
For most teams, though, none of the above apply. The monitoring stack is a necessary, not a sufficient, part of keeping the product up. It should cost the smallest amount of time and attention it can.
Try the opposite
If you’ve been maintaining a DIY stack and it’s consumed more engineering attention than you’d expected, that’s not a failure of your execution - it’s the default outcome. Get started with AlertKick; install the agent on a test host; compare the alerts that come out in the first week against the ones your current stack produces.
The features tour is the short version of the pitch. The point is that you should be writing product, not rules files.