What eBPF actually is - and why it's finally practical to run
eBPF is the reason modern runtime security works. Historically it's come with an enterprise price tag and a team to match. Here's what it does, why that's changed, and what AlertKick gives you on day one.
The AlertKick team
If you run servers and you’ve shopped for runtime threat detection recently, you’ve seen the word eBPF on every vendor’s page. You’ve probably also noticed that the products built on top of it are priced like enterprise software, because they were built for enterprise buyers.
eBPF is genuinely the right answer to the runtime-security question. The interesting thing that’s happened over the last couple of years is that it’s finally possible to ship it at a price and complexity level any team can adopt - without a security specialist on staff or a multi-week tuning project. That’s the shift AlertKick is built around.
Here’s what eBPF actually is, what it’s good for, and what you get when it arrives with sensible defaults instead of a six-month tuning project.
The one-paragraph explanation
eBPF is a mechanism built into the Linux kernel that lets userspace programs safely run small, sandboxed instructions inside kernel code paths. You can hook a syscall, a network event, a filesystem operation, a scheduler tick - the kernel verifies the program can’t crash or hang, then runs it in-kernel and reports results back up. That means you can observe what your processes genuinely did, down to the system call level, without modifying any of them and without turning on invasive debug logging.
For security, that gives you something nothing else can: real-time visibility into behaviour, at the layer where behaviour can’t lie.
Why this matters more than log-based monitoring
Logs are a claim. The process tells the log what it did. An attacker can disable, edit, or silence the log. An attacker can write plausible-looking entries. An attacker can replace the binary with one that just doesn’t write logs. Every serious intrusion playbook starts with some version of “silence the telemetry”.
File-integrity and static scanning are late. By the time a malicious binary is on disk, you’re already compromised. You’re just finding out after the fact.
eBPF observes behaviour. Every exec, every connect, every open, every capability change. It watches these from outside the process, from inside the kernel, at a layer the process cannot reach. You can turn off the logs, but you cannot turn off the kernel.
Concretely, that catches patterns like:
- Someone
exec-ing a shell inside a container that was supposed to be immutable and long-running. - A process making a network connection it’s never made before, to an address you don’t recognise.
- A cron job suddenly gaining capabilities (
CAP_SYS_ADMIN,CAP_NET_RAW) it never had last week. - A binary executing from
/tmpor/dev/shm- the classic pattern for fileless malware. - Crypto miners, by the shape of their syscall footprint, independent of the filename they use.
None of those depend on the attacker leaving behind a nice log line or a known-bad file signature.
Why this used to be out of reach
Three reasons, roughly.
Running eBPF well used to need specialists. The raw interface is unfriendly - bytecode, kernel verifier semantics, map types, ring buffers. You didn’t write it by hand; you leaned on a framework. The best open-source framework is powerful but ships with thousands of rules and assumes you’ve got the time to tune them to your environment. That tuning is a multi-week project for somebody who knows what they’re doing.
Raw eBPF is noisy. On a typical Linux server, the default detection rulesets will produce dozens of events per day. Package managers trigger them. Deploy scripts trigger them. Backup processes trigger them. Unless someone on your team spends a couple of weeks baselining your specific environment, the signal-to-noise ratio is bad enough that the team stops reading the channel within a fortnight. At that point you don’t have security; you have a tool you pay for.
Shipping eBPF events to a backend at scale is expensive. At a thousand hosts, you can be pushing hundreds of gigabytes of event data a day. The products that handle that scale are priced for the buyers who run a thousand hosts - which is not most of us.
Put together, these three meant that for a long time, the realistic options were: pay enterprise prices and staff a specialist to run it, or don’t bother. Most teams didn’t bother.
What’s changed
Managed agents matured. You don’t have to understand verifier semantics any more. A well-built agent ships with production-tuned defaults and a supervisor that keeps the kernel attachments healthy through reboots, kernel upgrades, and container restarts. It installs in a minute and gets out of your way.
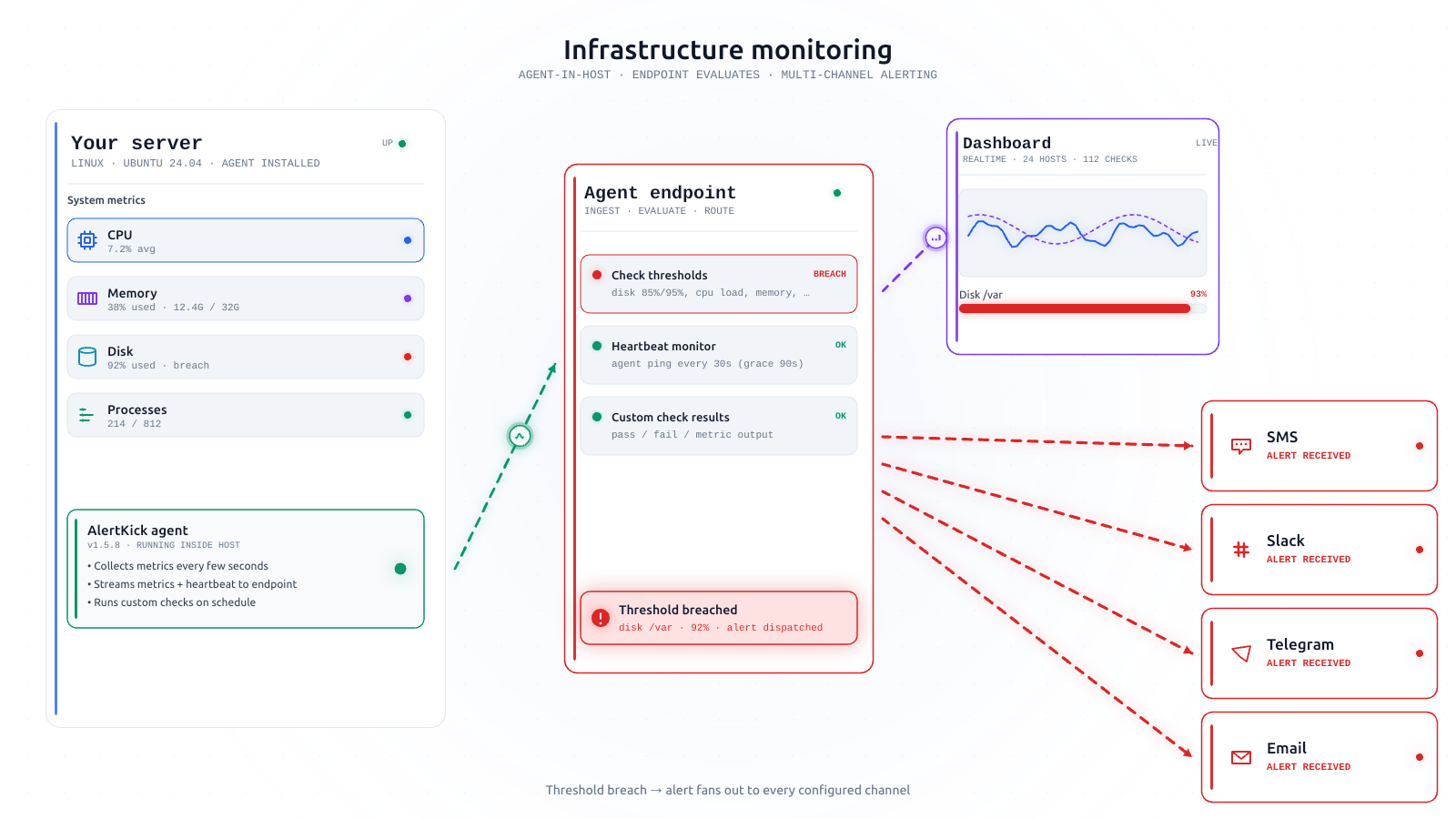
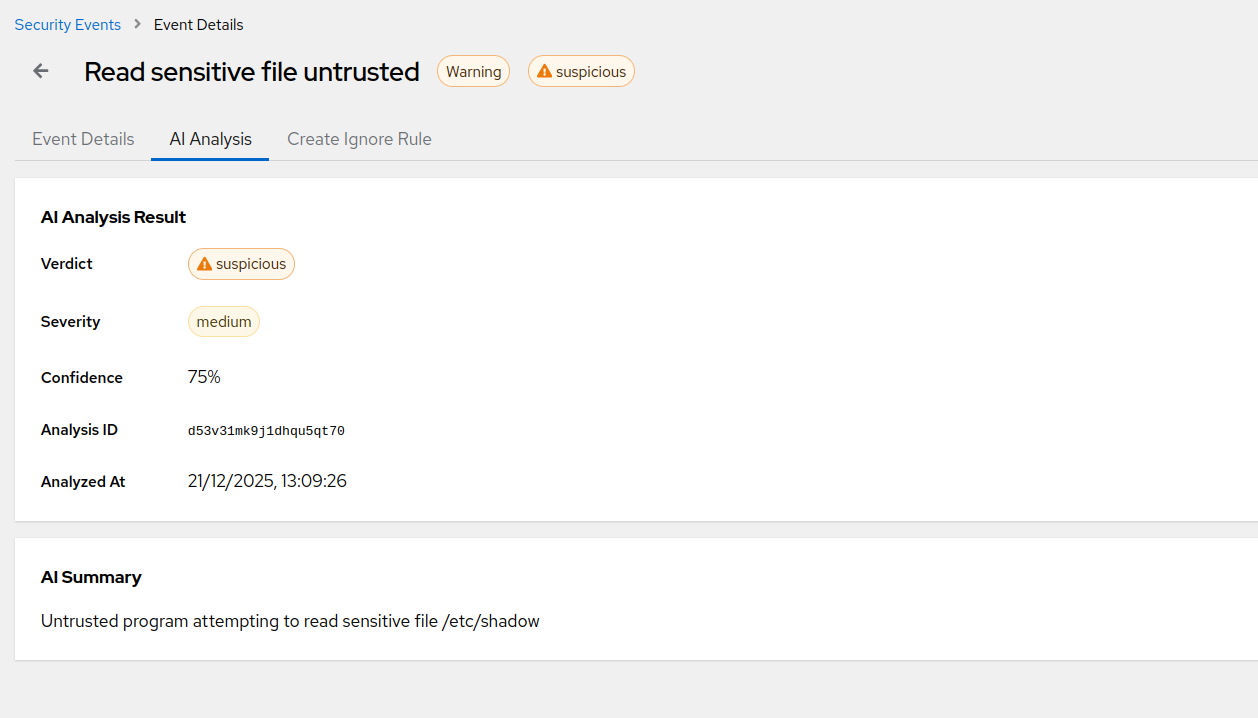
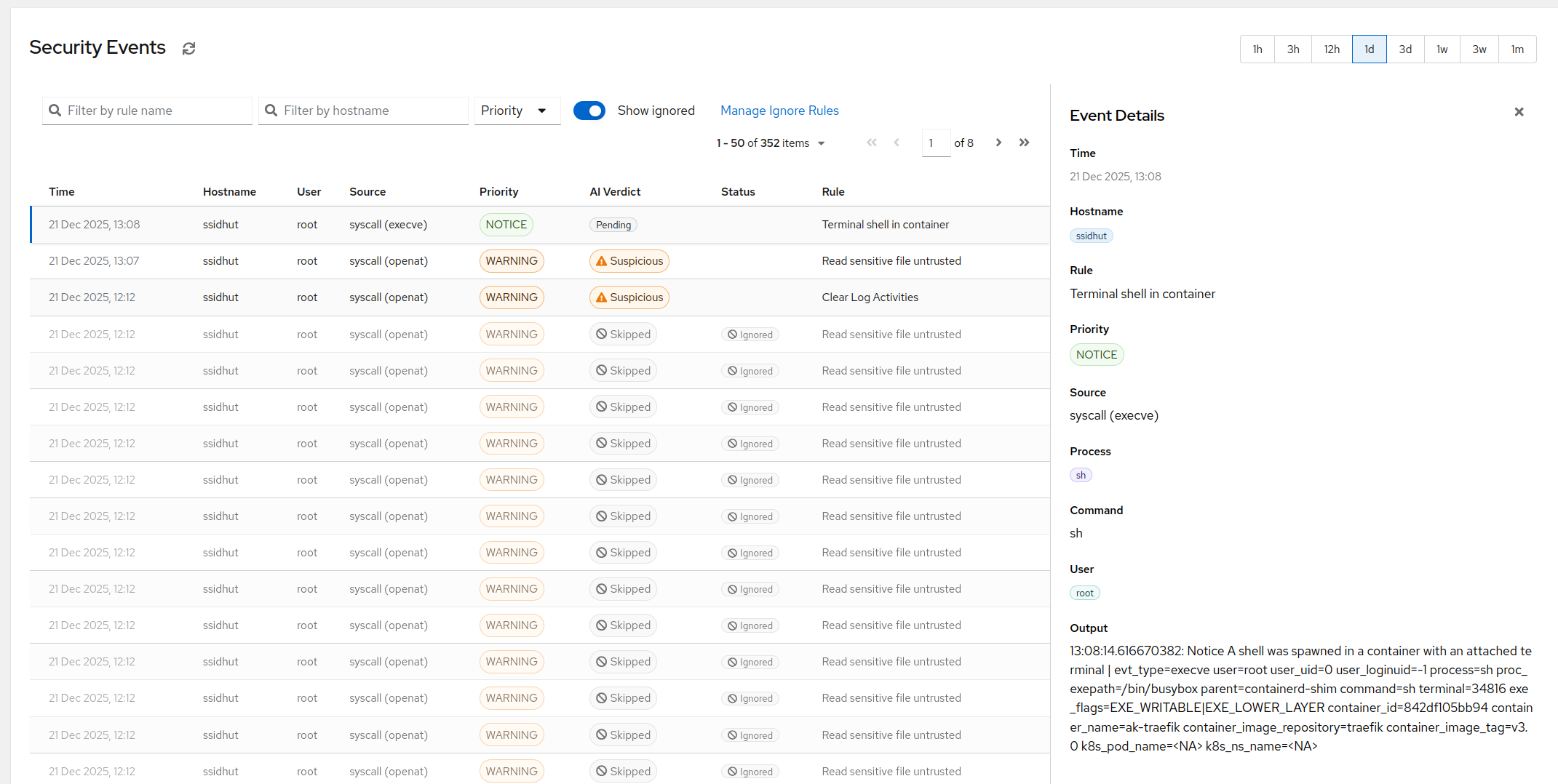
AI triage became genuinely useful for this. An eBPF event is a JSON blob describing “process curl executed on host web-03 with args https://…”. Is that bad? A human takes thirty seconds to decide, given context about the host and the deploy schedule. A well-prompted AI triage layer, given the same context, takes a second and gets the easy cases - which are most of them - right. That pre-filtering is the single biggest change in the last two years, because it’s the difference between “useful tool” and “tool nobody has time to look at”. In AlertKick’s dashboard you see the triage verdict inline with every event, along with the reasoning, so you can spot-check whenever you want.
The event-storage economics shifted. Enough that the per-host cost of shipping eBPF events to a managed backend is no longer the pacing bottleneck.
None of these changes are theoretical. They’re what make it possible for us to include runtime security in the same product as the rest of your monitoring, on one bill - no separate enterprise contract, no specialist to run it. Three years ago, that sentence would have been a lie.
What AlertKick gives you out of the box
When you install the AlertKick agent on a Linux host and enable the security module, these detections are on by default. You don’t configure them. You don’t write a rule. They’re already there.
- Shell-in-container - the single most useful runtime-security detection. Interactive shells in containers that were not designed to host one almost always mean something is wrong.
- Privilege escalation - a process gaining capabilities mid-execution, or the classic setuid pattern.
- Reverse shells and unusual bind patterns - processes listening on sockets they shouldn’t be.
- Memory-resident binaries - executables launched from
/tmp,/dev/shm, ormemfd. The fileless-malware pattern. - Crypto miner signatures - caught by syscall fingerprint rather than filename, which makes them resistant to renaming.
- Compliance-relevant file writes - edits to
/etc/passwd,/etc/shadow,/etc/sudoers, and the paths that sit inside a PCI DSS cardholder-data environment scope.
Every one of those is mapped to the relevant MITRE ATT&CK technique. You don’t see “rule #4782 triggered” - you see “T1059.004: Unix shell command-line interpreter, inside container payments-api.” You know what that means without a glossary.
And every event passes through the AI triage layer before it ever lands in your alerting channel. A typical week, on a typical fleet, produces between zero and a couple of events that actually page someone. The rest are visible in the dashboard for anyone auditing the triage decisions, with the AI’s reasoning attached to each one.
What it isn’t
eBPF runtime security is not endpoint protection for laptops, not an antivirus, not a network firewall, and not a substitute for patching or secret rotation. It won’t stop a phishing attack against an admin’s workstation. It won’t catch a compromised supply chain that ships a well-behaved malicious binary to every customer.
What it will do is catch the post-exploitation phase - the moment a successful attacker starts doing things on your servers. That’s the stage at which every other layer of defence has already failed. It’s the stage at which you most want to know.
Try it
If you’ve been avoiding runtime security because the existing options are priced for someone else, the eBPF feature page is where to start. Get started and the agent installs in about a minute on the test host of your choice.
The next post in this series will go deeper into the AI triage layer - what it actually does to an event, what it gets right, and where we’ve had to tune it.