Why we built AlertKick
Monitoring infrastructure is a pain in the ass. It takes numerous tools, each needing code and config, and once it breaks the team ends up with a dedicated monitoring person whose only job is keeping the stack alive. That's not a good outcome. So we built something opinionated.
The AlertKick team
Anyone who’s set up monitoring for production infrastructure knows the shape of the job.
You need checks on every host. You need synthetic probes on every endpoint. You need heartbeats on every scheduled job. You need security coverage. You need a way to page people, a way to escalate, a way to silence, a way to schedule. Each of those is a product category with a dozen options and its own mental model, and none of them compose cleanly with each other.
So teams stitch a stack together. One thing for infrastructure metrics, another for log-based alerts, another for synthetic uptime, another for cron heartbeats, another for on-call, and - for the serious setups - something else again for runtime security. Each one needs its own configuration file, its own rules language, its own deploy pipeline, its own upgrade schedule, its own dashboards. Glue code gets written. Custom exporters get written. YAML gets written until people start dreaming in it.
That stack works, sort of. Then it breaks, frequently. When it breaks, it breaks in the way stacks always break: in the cracks between the tools. The metric that should have fired an alert never made it from exporter to collector. The alert that did fire didn’t route to the right channel. The pager that should have escalated went to someone who left the company six months ago.
At that point, the team notices it’s spending more time maintaining the monitoring system than using it. And inevitably, the team solves that the only way it can - someone becomes the monitoring person. Their whole week is keeping the stack alive. That’s not a great outcome for them. It’s also not a great outcome for the team, because every minute that person spends on monitoring is a minute they’re not building the product.
The opinion behind AlertKick
AlertKick is the thing we wanted to exist back then. It’s one agent, one dashboard, one bill. You install it, you get monitoring that makes sense on day one, and then you go and do something more interesting with your week.
It is deliberately opinionated, not configurable. That word matters, so it’s worth being specific about what it means.
A configurable tool gives you the ability to do anything. It hands you a rules language, a metrics pipeline, a query DSL, a templating system, and says “you figure out what to monitor”. Configurability is a wonderful feature when the buyer has a team with the time and expertise to use it. Every company big enough to have a dedicated monitoring engineer benefits from configurability.
For everybody else, configurability is a tax. You pay for it in the time you spend deciding what the defaults should be. You pay for it in the months of drift before the defaults are actually right. You pay for it again every time somebody new joins the team and has to re-learn which of the ninety-seven rules apply to their service.
AlertKick takes the opposite position. Years of SRE work taught us what matters and what doesn’t - which checks actually catch incidents, which thresholds actually matter, which alerts should page a human and which should just sit in a feed. That’s baked into the product as defaults. You install the agent, it picks up what’s running on the box, and the right checks are already there.
That is the entire product thesis. Everything else - heartbeats, alerting, on-call, eBPF-based runtime security, compliance - follows the same shape. Defaults that are right for the median case. Small number of levers. No YAML dynasty.
What it looks like in practice
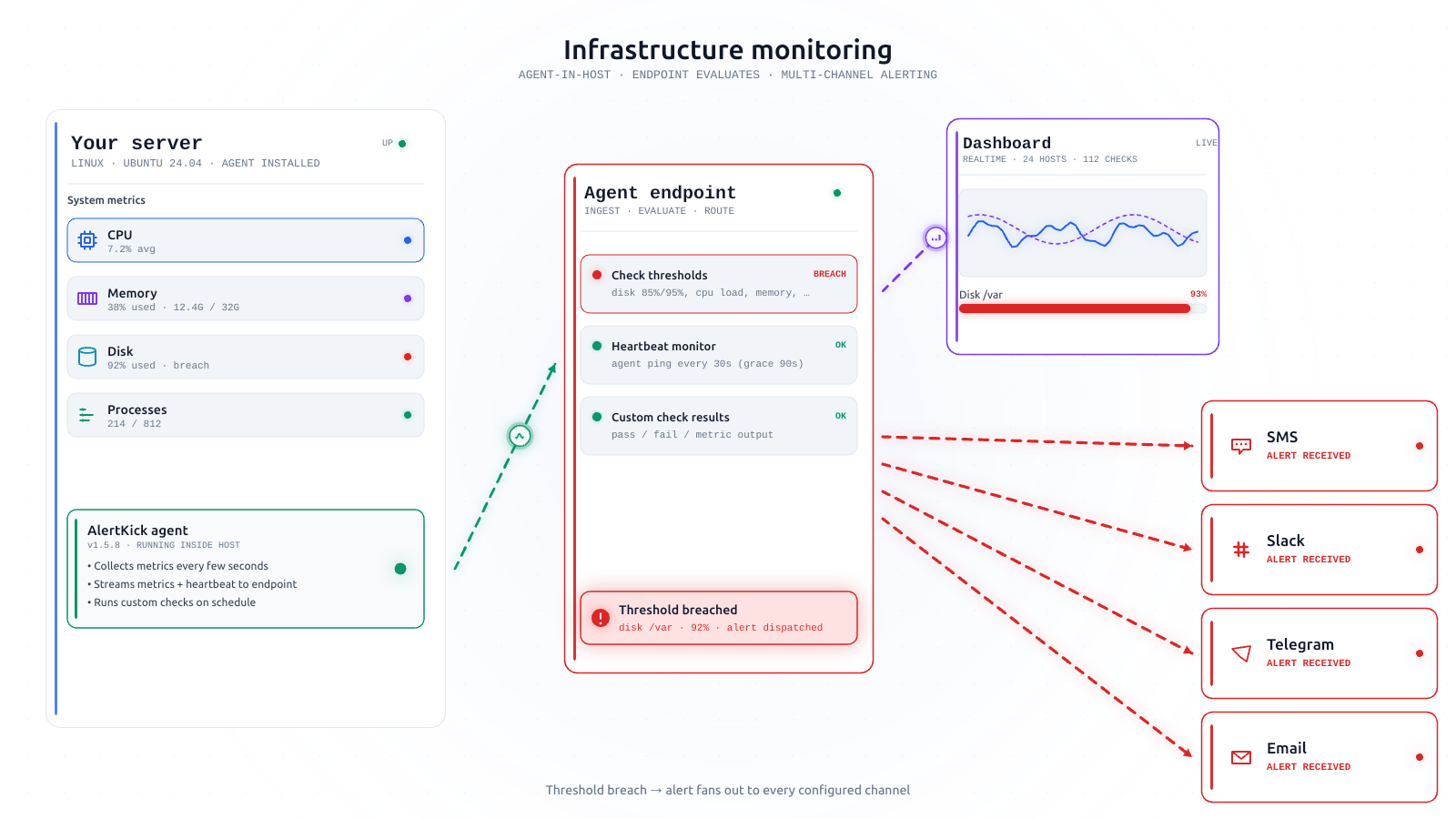
- One agent to install, for Linux servers, containers, and the like. It handles infrastructure metrics, custom checks, heartbeats, and runtime security in a single process.
- One dashboard. Hosts, alerts, heartbeats, security events, on-call schedule - all on one screen.
- Alerts that know where to go. Escalation policies that ship as sensible defaults and can be adjusted when you have a reason.
- Heartbeats, so you find out when a silent cron job has stopped running before the backup week discovers it for you.
- eBPF security, so the question “is anything weird happening on this server right now?” has a real answer, pre-triaged by an AI layer so nobody’s reading thirty events a day trying to figure out which two matter.
- An MCP server on top, so investigations from an AI assistant are a first-class thing.
One bill. Every feature on every plan - you add hosts and checks as you grow, but you never pay per seat, per metric, or per feature.
Who it’s for
AlertKick is built for teams that would rather not put a person on permanent monitoring duty. If that’s you, there’s something here that saves you time.
If you do have a dedicated observability team, a nuanced monitoring culture, and strong opinions about how your rules should be templated - you probably want something you can program. AlertKick is unlikely to be the right fit, and that’s fine.
What this blog is for
This blog exists to write openly about the product, the thinking, and the tradeoffs. Upcoming posts go into specific features - what AlertKick detects out of the box and why, what the default escalation levels do, how heartbeats catch silent failures that metrics don’t. Not sales pitches, but the actual “how and why”.
If you’re curious, the features page is the short tour. If you want to try it, get started - the agent installs in about a minute.
Thanks for reading.